codex-resume는 OpenAI Codex CLI의 로컬 세션 로그를 검색하고,
필요한 세션을 골라 codex resume <session-id>로 이어가기 위한 Windows 친화형 TUI 도구다.
처음에는 외부 의존성을 거의 쓰지 않고 Node.js 기본 모듈만으로 구현했다. 빠르게 동작하고 설치가 단순하다는 장점은 있었지만, 실제 화면을 보고 나니 방향을 바꿔야 했다. 이 글은 그 의사결정 기록이다.
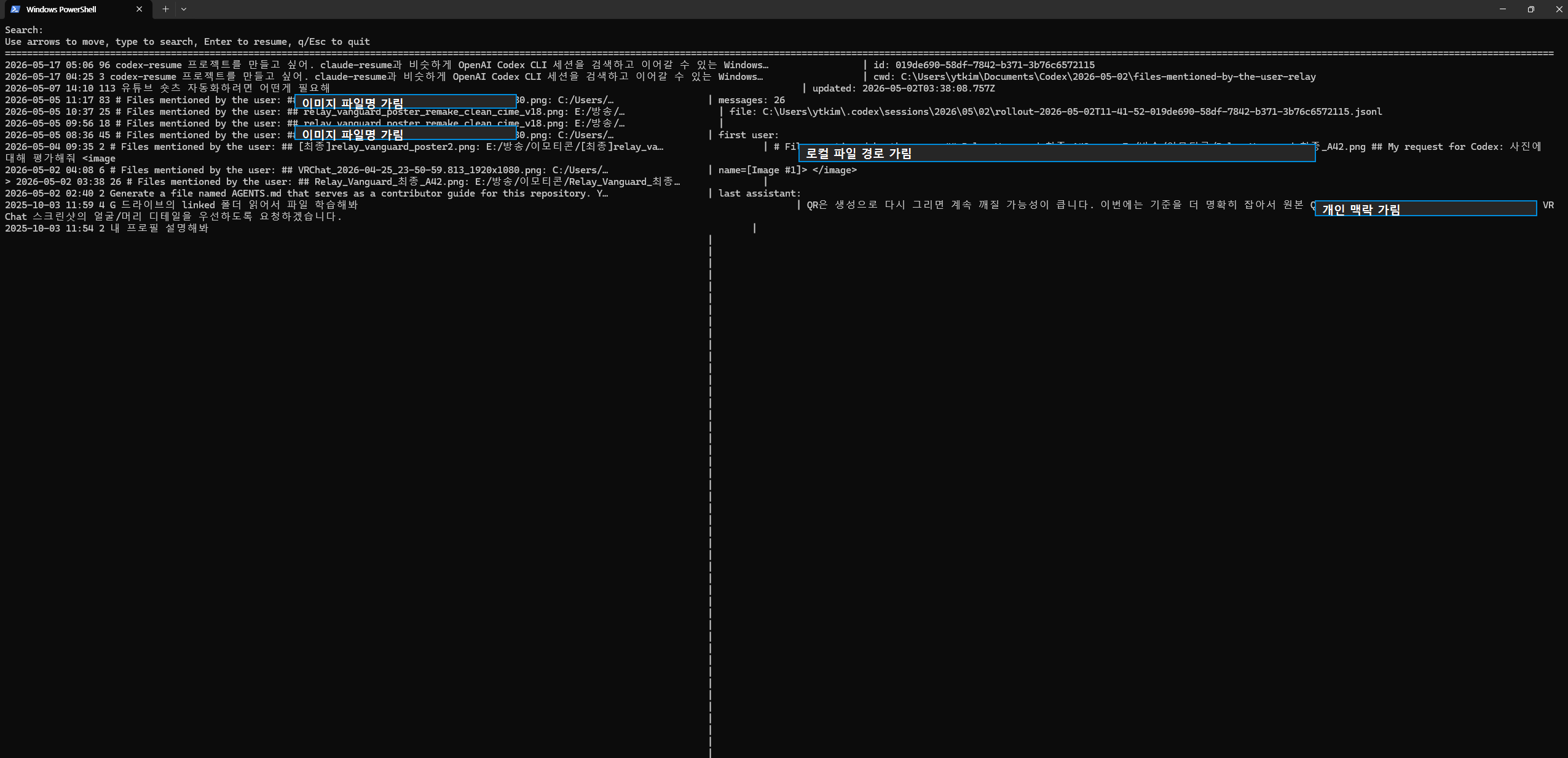
위 화면은 초기 codex-resume의 raw TUI다.
기능적으로는 세션을 찾고 이어갈 수 있었지만, 메뉴 정보가 직관적이지 않았고 한글·긴 경로·긴 요청이 섞일 때 화면이 쉽게 깨졌다.
첫 구현
처음 구현한 기능은 다음과 같았다.
%USERPROFILE%\.codex\sessions아래 JSONL 로그 스캔session_meta,user_message,response_item,event_msg파싱- 첫 사용자 메시지와 마지막 assistant 메시지로 preview 생성
codex resume <session-id>로 handoff- PowerShell/CMD wrapper 제공
이 접근은 빠르게 동작하는 장점이 있었다.
설치가 거의 필요 없고, 실제 Codex 세션을 읽어 list, doctor, index, resume 명령을 바로 검증할 수 있었다.
하지만 PowerShell에서 직접 실행한 화면을 캡처해서 보니 문제가 분명해졌다.
실제 화면에서 보인 문제
첫 번째 문제는 표시 폭 계산이었다.
한글, 긴 경로, 이미지 파일명, 긴 사용자 요청이 섞이자 좌우 구분선과 텍스트가 겹쳤다.
문자열 길이와 터미널 표시 폭이 다르기 때문에 단순 length 기준으로는 안정적인 레이아웃을 만들기 어렵다.
두 번째 문제는 세션 의미 파악이 어렵다는 점이었다.
첫 사용자 메시지와 마지막 응답을 그냥 잘라 보여주면, 결국 raw 로그를 조금 예쁘게 보여주는 정도에 그친다.
claude-resume에서 좋았던 것은 raw preview가 아니라 LLM이 요약한 “이 세션의 의미”였다.
세 번째 문제는 TUI 상호작용의 완성도였다. 스크롤, 포커스, 선택 상태, 검색 입력, 상세 패널 표시 같은 요소는 직접 만들 수는 있지만, 계속 보수해야 한다. 처음부터 도구의 핵심이 TUI라면 검증된 TUI 라이브러리를 쓰는 편이 맞다.
비교 기준: claude-resume에서 좋았던 점
비교 기준으로 삼은 것은 이전에 만든 claude-resume였다.
Claude Code의 기본 resume 화면은 세션 ID와 시간 중심이라 대화가 많아지면 찾기가 어렵다.
그래서 claude-resume에서는 Python Textual로 두 패널 TUI를 만들고, 백그라운드에서 claude -p를 호출해 각 세션을 한 줄로 요약하게 했다.
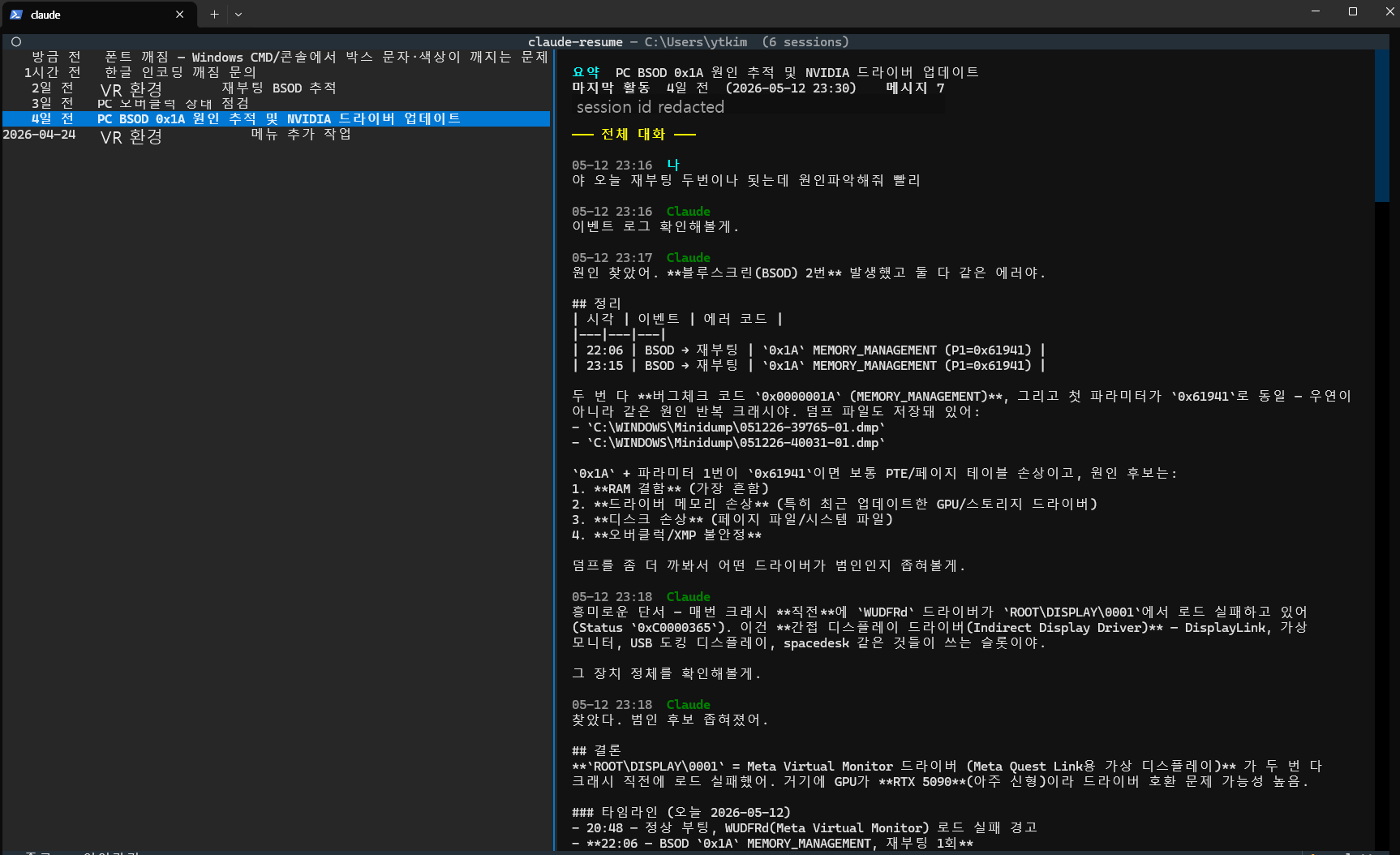
이 화면은 codex-resume 글의 주인공이 아니라 비교 대상이다.
좋았던 점은 명확했다.
- 세션 ID가 아니라 “무슨 일을 하던 대화였는지”를 기준으로 찾을 수 있다.
- 긴 JSONL 로그를 직접 열어보지 않아도 된다.
- 요약은 캐시되므로 다음 실행부터 빠르게 볼 수 있다.
- UI가 두 패널로 나뉘어 있어 목록과 상세 내용을 동시에 비교할 수 있다.
결론: 외부 TUI 라이브러리는 필요하다
처음에는 dependency-free 구현이 더 단순하고 배포하기 쉽다고 봤다. 하지만 실제 화면을 보고 판단이 바뀌었다.
codex-resume는 단순 CLI가 아니라 과거 AI 작업 히스토리를 찾는 브라우저다.
그렇다면 화면 품질은 부가 기능이 아니라 핵심 기능이다.
그래서 기본 UI는 Node.js TUI 라이브러리인 blessed 기반으로 바꾸고, 기존 의존성 없는 picker는 fallback으로 남기는 방향으로 수정했다.
이 결정은 claude-resume에서 Textual을 사용한 이유와 같다.
- 목록과 상세를 안정적으로 분리하기 위해
- 키보드 이동, 스크롤, 포커스 상태를 직접 유지보수하지 않기 위해
- 세션 요약을 중심에 둔 UI를 만들기 위해
- Windows Terminal / PowerShell에서 실제로 보기 좋은 도구로 만들기 위해
다음 과제
codex-resume의 다음 단계는 claude-resume처럼 LLM 요약 캐시를 붙이는 것이다.
Codex 세션 로그는 ~/.codex/sessions/YYYY/MM/DD/*.jsonl 형태로 저장되어 있고, 실제 대화는 user_message, response_item, event_msg 안에 들어 있다.
이 내용을 요약 provider에 넘기고, 결과를 %USERPROFILE%\.codex\codex-resume\session-index.json 또는 별도 summary cache에 저장하면 된다.
요약 provider는 처음부터 하나로 고정하지 않는 편이 좋다.
- OpenAI API를 쓰는 방식
- Codex CLI가 제공하는 비대화형 호출을 쓰는 방식
- 사용자가 이미 가진 다른 LLM CLI를 쓰는 방식
- 요약 없이 heuristic summary만 쓰는 fallback
중요한 것은 요약 자체보다도, 사용자가 “그때 무슨 작업을 하던 세션이지?”를 바로 알 수 있게 만드는 것이다.
claude-resume에서 얻은 교훈은 결국 이거였다.
세션 복구 도구의 본질은 ID를 보여주는 것이 아니라, 작업 기억을 다시 찾게 해주는 것이다.
다른 AI 에이전트에게 남기는 메모
이 작업을 이어받는 AI 에이전트는 codex-resume를 단순 세션 ID picker로 보지 말고, AI 작업 히스토리 브라우저로 봐야 한다.
- 기본 TUI는
blessed기반 split-pane 구조를 유지한다. - dependency-free picker는 fallback으로만 둔다.
- 다음 핵심 작업은 LLM 요약 캐시다.
- 공개용 스크린샷은 반드시 민감한 세션명, 로컬 경로, 개인 파일명을 가린다.
- 관련 문서는
claude-toolkit과GitHubPageMaker의 AI Workflow 글에 같이 남긴다.